銀ねこアトリエ
Home
Blog
ウェブ制作
CMS
SEO対策・デジタルマーケ
海外ノマド生活
キャリアアップ
かみーゆ徒然記
About Me
かみーゆの本棚
Contact
MENU
銀ねこアトリエ
海外ノマドブログ
ウェブ制作
Python
python でスクレイピングして検索上...
SHARE
Facebook
python でスクレイピングして検索上位100件をCVS出力
公開日:
2022.03.10
メンテナンス日:
2022.03.30
# Python
Gatsbyホットリロード中他のディバイスからアクセスする方法
2020.12.07
# npm
DockerでWordPress構築|シンプル&軽量な開発環境の作成手順
2021.12.22
# Docker
# WordPress
全部使ったことある?便利なCSS関数12選!!
2021.05.21
# CSS
CSSの変な仕様あるあるを力一杯列挙してみた
2019.07.20
# CSS
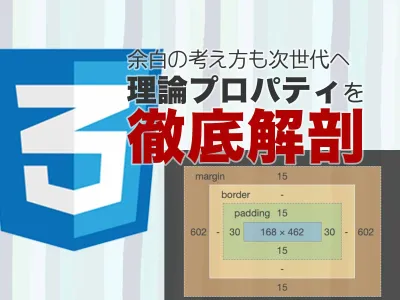
次世代CSSは論理プロパティ!margin-block、margin-inlineを徹底解剖!
2021.01.28
# CSS
【コピペで動く】CSS counter(カウンター)の使い方!実務で使える自動ナンバリング実装パターン3選
2020.03.29
# CSS